* Single-Row Functions (단일 행 함수)
-> 행마다 함수가 적용되어 결과를 반환함. 세부적으로 아래와 같이 구분할 수 있는데, 대상이 되는 데이터의 타입에 따라 이를 분류하고 있다.
1) Number Functions (숫자 함수)
-> 숫자 데이터 타입의 값을 조작하여 변환된 숫자 값을 반환한다.
2) Character Functions (문자 함수)
-> 문자 데이터 타입의 값을 조작하여 변환된 문자 값을 반환한다.
3) Datetime Function (날짜 함수)
-> DATE로 지정된 데이터 타입의 값에 적용한다.
4) Conversion Function (변환 함수)
-> 데티어 타입을 변환시켜 표현한다. 예를 들어 날짜를 문자로 변환하면서 년/월/일에 대해 식별력을 높이는 변환을 수행하고 있다.
5) Miscellaneous Single-Row Functions (기타 함수)
-> 기타 유용한 함수를 포함하고 있다.
* Aggregate Functions (집합 함수)
-> 하나 이상의 행(집합)을 대상으로 연산을 수행한 결과값을 반환한다. 앞에서 본 단일 행 함수는 하나의 행을 대상으로 수행된다는 점에서 차이가 있다. 부서의 평균이나 특정 제품의 매출 수량 합을 구할 때 사용된다.
* Analytical Functions (분석 함수)
-> 행의 집단에 대해 연산이 이루어진다는 점에서 일반 그룹 함수와 유사하다. 그러나 일반 그룹 함수는 하나의 집단에 대해
하나의 결과가 RETURN 되지만 분석용 함수는 하나의 집단에 대해 여러 가지 기준을 적용해서 여러 개의 결과가 RETURN 될
수 있다. 예를 들어 대량의 데이터를 대상으로 누적 합계, 순위, 이동 평균 등을 구하려고 할 때 분석용 함수를 유용하게 사용할
수 있다.
* Regular Expression (정규 표현식)
-> Oracle 10g에서 새로 도입된 정규 표현식(Regular Expression)을 구현하기 위해 Oracle은 기존 함수의 기능을 확장한 새로운 함수를 제공하고 있다.
============================================================
3.1 단일 행 함수(Single-Row Functions)
-> 단일 행 함수는 함수가 행마다 적용된다. 어떤 테이블에 10개의 행이 있고 질의문에 조건이 없다면, 10개의 행 모두에 단일 행 함수가 적용되어 변환된 결과를 반환한다.
1) 숫자 함수(Number Functions)
-> 숫자 데이터 타입의 값을 조작하여 변화된 숫자 값을 반환하는 함수이다.
(1) MOD 함수
MOD(m, n)
-> m을 n으로 나누었을 때 나머지를 반환한다.
SQL> SELECT MOD(10, 3) “Modules”
2 FROM dual;
Modules
———-
1
* dual 테이블이란?
-> FROM 절에 사용한 dual 테이블은 종종 연산이나 날짜에 대한 정보를 보기 위해 사용하는 Oracle이 제공하는
테이블이다. 이 테이블의 특징은 데이터가 한 개의 행으로 구성되어 있어 별도의 테이블 생성 없이 보는 것을 가능하게 한다.
예를 들어 반지름이 5인 원의 면적을 구하는 계산을 해보자. 이때 부서 테이블을 이용해서 질의해 보면 연산의 결과값이
반복해서 나타나게 된다. 즉 부서 테이블의 행의 수만큼 나타난다. 사용자는 동일 결과를 반복해서 볼 이유가 없으므로 하나의
행만을 가진 dual 테이블을 이용해서 결과를 보곤 한다.
(2) ROUND 함수
ROUND(m, n)
-> m을 소수점 n + 1 자리에서 반올림한 결과를 반환한다.
ex) 18.354를 소수점 셋째 자리에서 반올림한 결과를 반환하라.
SQL> SELECT ROUND(18.354, 2) “Round”
2 FROM dual;
Round
———-
18.35
ex) 18.354를 정수 일의 자리(숫자 8)에서 반올림한 결과를 반환하라.
SQL> SELECT ROUND(18.354, -1) “Round”
2 FROM dual;
Round
———-
20
-> n 값이 양수이면 소수점이 우측으로 이동하며, 음수이면 좌측으로 이동한다. 18.354에서 우측으로 소수점 2자리
이동을 하면 소수점 이하 5 다음에 위치하여 소수점 이하 즉 4에 대해 반올림을 한다. 편의상 n + 1 자리에서 반올림을
수행하여 결과를 반환한다고 보면 된다. 참고로 반올림 대신 내림을 수행하는 TRUNC() 함수도 있다.
다음은 ROUND() 함수를 이용하여 급여 대한 평균을 소수 둘째 자리에서 반올림한 결과이다.
SQL> SELECT department_id, ROUND(AVG(salary), 1) AS AvgSalary
2 FROM employees
3 GROUP BY department_id;
DEPARTMENT_ID AVGSALARY
————- ———-
100 8600
30 4150
7000
20 9500
70 10000
90 19333.3
110 10150
50 3475.6
40 6500
80 8955.9
10 4400
DEPARTMENT_ID AVGSALARY
————- ———-
60 5760
12 rows selected.
(3) WIDTH_BUCKET 함수
WIDTH_BUCJET(expr, min_value, max_value, num_buckets)
-> 어떤 값의 최소에서부터 최대값을 설정하고 bucket을 지정하여 임의의 값이 지정된 범위 내에서 어느 위치에 있는가를 반환한다.
ex) 0부터 100까지를 10개의 구간으로 나눈 후 92가 몇 번째 구간에 속하는지를 알아본다.
SQL> SELECT WIDTH_BUCKET(92, 0, 100, 10) “Score”
2 FROM dual;
Score
———-
10
-> bucket의 사전적인 의미는 ‘물통’, ‘bucket으로 물을 나르다’의 의미이다. 위 함수에서는 어떤 값의
최소에서부터 최대값이 설정되면 범위 내 bucket을 지정하여 임의의 값이 이 범위 내에서 어느 위치에 있는지를 알 수 있다.
ex) 다음은 hr 소유의 사원 테이블에서 급여에 대해 등급을 정의한 것이다.
SQL> SELECT employee_id, salary, WIDTH_BUCKET(salary, 0, 20000, 10) “Grade”
2 FROM employees
3 WHERE department_id = 50;
2) 문자 함수(Character Functions)
-> 문자 데이터 타입의 값을 조작하여 문자 값을 반환한다.
(1) LOWER 함수
LOWER(char)
-> 입력된 문자 값을 소문자로 변환한다.
ex) ‘Korea’라는 문자열을 모두 소문자로 변환한 후 ‘Lower’로 나타낸다.
SQL> SELECT LOWER(‘Korea’) “Lower”
2 FROM dual;
Lower
—–
korea
-> 테이블에 저장되어 있는 영문자에 대해서 Oracle은 대소문자를 구분한다. WHERE절에서 지정된 값에 대해 정확하게 대소문자가 표현되어야 한다.
ex) 사원번호 139번인 ‘Seo’의 정보를 얻어온다. 만약 ‘Seo’라는 이름이 있다면 대소문자에 관계없이 아래와 값이 LOWER() 함수를 이용하여 질의문을 작성할 수 있다.
SQL> SELECT employee_id, last_name
2 FROM employees
3 WHERE last_name = ‘Seo’;
EMPLOYEE_ID LAST_NAME
———– ————————-
139 Seo
SQL> SELECT employee_id, last_name
2 FROM employees
3 WHERE LOWER(last_name) = ‘seo’;
EMPLOYEE_ID LAST_NAME
———– ————————-
139 Seo
이와 비슷하게 모든 문자값을 대문자로 반환하는 UPPER() 함수도 있다.
(2) SUBSTR 함수
SUBSTR(string, position, substring_length)
-> 문자열에서 일부 문자값을 선택적으로 반환한다.
ex) ‘Korea Economy’ 문자열의 처음부터 다섯 자리까지의 문자를 반환한다.
SQL> SELECT SUBSTR(‘Korea Economy’, 1, 5) “substr”
2 FROM dual;
subst
—–
Korea
-> 문자열 ‘Korea Economy’에서 시작 문자 위치가 1 그리고 문자 5개를 선택하여 반환함으로 위와 같은 결과를 얻을 수 있다.
3) 날짜 함수(Datetime Functions)
-> DATE로 지정된 데이터 타입의 값에 적용한다.
(1) SYSDATE 함수
SYSDATE
-> 시스템의 설정된 날짜 값을 반환한다.
ex) 현재 시스템의 날짜를 가져온다.
SQL> SELECT SYSDATE
2 FROM dual;
SYSDATE
———
30-MAR-09
(2) ADD_MONTHS 함수
ADD_MONTHS(date, integer)
-> 지정한 날짜 중 해당 월에 정수를 더한 값을 반환한다.
ex) 현재 날짜에서 30개월 뒤의 날짜를 확인한다.
SQL> SELECT TO_CHAR(ADD_MONTHS(SYSDATE, 30), ‘YYYY-MM-DD’)
2 FROM dual;
TO_CHAR(AD
———-
2011-09-30
-> 첫 번째 인자로부터 현재의 날짜인 ‘2009년 3월 30일’을 얻고, 두 번째 인자로부터 얻은 값 ’30’을 첫 번째
값의 월에 더한 결과를 반환한다. 반환되는 겂은 날짜 타입이며, 이를 문자로 형 변환하여 쉽게 식별할 수 있도록 하였다.
(3) LAST_DAY 함수
LAST_DAY(date)
-> 해당하는 월의 마지막 일을 반환한다.
ex) 현재의 날짜로부터 마지막 날짜까지 남은 일 수를 반환한다.
SQL> SELECT LAST_DAY(SYSDATE) – SYSDATE “Remain Days”
2 From dual;
Remain Days
———–
1
-> 현재의 날짜 ‘2009년 3월 30일’로부터 3월의 마지막 날짜를 LAST_DAY() 함수로부터 얻어내고 있다.
반환되는 값 ‘2009 3월 30일’로부터 현재의 날짜를 뺀 결과를 반환한다. 즉 2009년 3월 30일은 이 달 말일로부터
1일 남아 있음을 알 수 있다. 반환되는 값은 숫자이며, 단위는 ‘일(day)’이다.
(4) MONTHS_BETWEEN 함수
MONTHS_BETWEEN(date1, date2)
-> 날짜와 날짜 사이의 기간을 ‘월(month)’로 나타낸다. date1이 date2보다 큰 값이다.
ex) 현재 달의 마지막 날짜로부터 오늘 날짜를 뺀 결과를 월로 나타낸다.
SQL> SELECT MONTHS_BETWEEN(LAST_DAY(SYSDATE), SYSDATE) “Remain Months”
2 FROM dual;
Remain Months
————-
.032258065
-> LAST_DAY() 함수의 예제와 동일한 경우이다. 단, 반환되는 단위는 ‘월(month)’이다. 즉, 2009년
3월 30일은 이 달 말인인 2009년 3월 31일로부터 0.032258065 개월 남아 있음을 알 수 있다.
4) 변환 함수(Conversion Functions)
(1) TO_CHAR(datetime)
TO_CHAR(datetime, ‘format’)
-> DATE 관련 타입을 VARCHAR2 데이터 타입으로 변환한다.
ex) 시스템 날짜를 ‘연-월-일 시-분-초’의 형식으로 변환해 본다.
SQL> SELECt TO_CHAR(SYSDATE, ‘YYYY-MM-DD HH24:MI:SS’) “sysdate”
2 FROM dual;
sysdate
——————-
2009-03-30 02:43:08
-> 날자 데이터 타입의 값을 일정한 양식(format)에 의해 문자로 변환한다. 날짜의 특정 부분을 표현할 수 있는 방법은 아래와 같다.
구성요소 : 의미
D : 요일 번호(1 – 7)
DAY : 요일명
DD : 일(1 – 31)
DY : 요일명 약자
HH : 시 (1 – 12)
HH24 : 시(0 – 23)
MI : 분(0 – 59)
MM : 월(1 – 12)
MON : 월 이름 약자
MONTH : 월 이름
SS : 초(0 – 59)
YEAR : 년도
YYYY : 4자리 년도
ex) 시스템 날짜를 위와는 다른 방식으로 표현해 본다.
SQL> SELECT TO_CHAR(SYSDATE, ‘YEAR-MON-DY HH:MI:SS’) “sysdate”
2 FROM dual;
sysdate
—————————————————————————–
TWO THOUSAND NINE-MAR-MON 02:46:43
ex) 다음은 1998년 월별 입사자의 수를 계산하는 예이다.
SQL> SELECT TO_CHAR(hire_date, ‘YYYY-MM’), COUNT(last_name)
2 FROM employees
3 WHERE TO_CHAR(hire_date, ‘YYYY’) = ‘1998’
4 GROUP BY TO_CHAR(hire_date, ‘YYYY-MM’);
TO_CHAR COUNT(LAST_NAME)
——- —————-
1998-05 1
1998-09 1
1998-01 2
1998-02 3
1998-08 1
1998-04 3
1998-07 3
1998-12 1
1998-06 1
1998-03 5
1998-11 2
(2) TO_CHAR(number)
TO_CHAR(number, ‘format’)
-> NUMBER 타입을 VARCHAR2 데이터 타입으로 변환한다. VARCHAR2는 가변 문자(Variable Character)의 의미로, 길이가 일정하지 않은 문자 값을 저장하는 데이터 타입이다.
ex) ‘20000’을 숫자 표현 양식 화폐 단위인 ‘$’로 표현해 본다.
SQL> SELECT TO_CHAR(20000, ‘$999,999’) “money”
2 FROM dual;
money
———
$20,000
-> 숫자 데이터 타입의 값을 일정한 양식(format)에 의해 문자로 변환한다. 이처럼 숫자의 특정 부분을 표현할 수 있는 방법은 아래와 같다.
숫자 : 형식 : 결과
123.45 : 999.999 : 123.450
123.45 : 9999 : 123
123.45 : $999.99 : $123.45
123.45 : L999.99 : 123.45
123.45 : S999.999 : +123.45
12345 : 999,999 : 12,345
-> L은 지역 화폐 단위를 나타낸다. 대한민국은 원화를 단위로 로 표현된다. S는 양수나 음수를 표시하는 부호를 나타낸다. 양수이므로 +로 표현한다.
5) 기타 함수(Miscellaneous Single-Row Functions)
(1) DECODE 함수
DECODE(expr, search, result, default)
-> ‘expr’과 각 ‘search’ 값을 비교하여 같으면 result 값을 반환한다. 같지 않다면 default 값을 반환한다.
ex) job_id가 ‘SA_MAN’혹은 ‘SA_REP’이면 판매 부서인 ‘Sales Dept’를, 그 외에는 다른 부서이므로 ‘Another’를 표시한다.
SQL> SELECT job_id,
2 DECODE (job_id, ‘SA_MAN’, ‘Sales Dept’, ‘SA_REP’, ‘Sales Dept’, ‘Another’)
3 “decode”
4 FROM jobs WHERE job_id LIKE ‘S%’;
JOB_ID decode
———- ———-
SA_MAN Sales Dept
SA_REP Sales Dept
SH_CLERK Another
ST_CLERK Another
ST_MAN Another
-> job_id가 대문자 S로 시작하는 것 중에서 ‘SA_MAN’과 ‘SA_REP’인 경우는 영업 부서임을 나타내기 위해
‘Sales Dept’로 표현하되 그 이외는 ‘Another’로 나타낸 예이다. 참고로 DECODE)_ 함수는 CASE 구문으로
표현할 수 있다. 다음은 CASE구문으로 표현한 예이다.
* CASE 구문을 이용한 표현
CASE value
WHEN expr1 THEN
구문1
WHEN expr2 THEN
구문2
ELSE
구문3
END CASE
SQL> SELECT job_id,
2 CASE job_id
3 WHEN ‘SA_MAN’ THEN
4 ‘Sales Dept’
5 WHEN ‘SA_REP’ THEN
6 ‘Sales Dept’
7 ELSE
8 ‘Another’
9 END CASE
10 FROM jobs
11 WHERE job_id LIKE ‘S%’;
JOB_ID CASE
———- ———-
SA_MAN Sales Dept
SA_REP Sales Dept
SH_CLERK Another
ST_CLERK Another
ST_MAN Another
(2) NVL 함수
NVL(expr1, expr2)
-> expr1이 NULL 값인 경우 expr2의 값을 반환한다.
ex) 커미션(commission_pct)이 없는 경우, 즉 NULL이면 0으로 표시한다.
SQL> SELECT employee_id, salary, NVL(commission_pct, 0) “commission_pct”
2 FROM employees
3 WHERE job_id = ‘IT_PROG’;
EMPLOYEE_ID SALARY commission_pct
———– ———- ————–
103 9000 0
104 6000 0
105 4800 0
106 4800 0
107 4200 0
* 다음은 자주 사용되는 단일 행 함수를 요약한 표이다.
함수이름 : 설명
* 숫자 함수 (Number Functions)
MOD(m, n) : m을 n으로 나누었을 때 나머지를 반환한다.
ROUND(m, n) : m을 소수점 n + 1 자리엣 반올림한 결과를 반환한다.
WIDTH_BUCKET(expr, min_value, max_value, num_buckets) : 어떤 값의 최소에서 최대값을 설정하고 bucket을 지정하여 임의의 값이 지정된 범위 내에서 어느 위치에 있는지를 반환한다.
CEIL(n) : 올림한 후 정수를 반환한다.
FLOOR(n) : 내림한 후 정수를 반환한다.
ABS(n) : 절대값을 반환한다.
NANVL(m, n) : 입력 값 m이 숫자가 아니라면 대체 n을 반환하고, 숫자라면 m을 반환한다.
TRUNC(n, [m]) : 인수 n 소수점자리 m이하를 절삭한다.
* 문자 함수 (Charater Functions)
LOWER(char) : 입력된 문자 값을 소문자로 변환한다.
SUBSTR(string, position, substring_length) : 문자열에서 일부 문자값을 선택적으로 반환한다.
ASCII(char) : 문자의 ASCII 값을 반환한다.
CHR(n [USING NCHAR_CS]) : 10진수 n에 대응하는 아스키 코드를 반환한다.
LENGTH(char)
LTRIM(char, [set]) : 문자열 char 좌측으로부터 set으로 지정된 모든 문자를 제거한다.
LPAD(expr1, n, [expr2]) : 지정된 자리수 n으로부터 expr1을 채우고, 왼편의 남은 공간에 expr2를 채운다.
REPLACE(expr, str1, [str2]) : 파라미터로 주어지는 첫 번째 문자열에서, 두 번째 문자열을 모두 세 번째 문자열로 바꾼 후 결과를 반환한다.
* 날짜 함수 (Datetime Functions)
SYSDATE : 시스템의 설정된 날짜 값을 반환한다.
ADD_MONTHS(date, integer) : 지정한 날짜 중 해당 월에 정수를 더한 값을 반환한다.
LAST_DAY(date) : 해당하는 월의 마지막 일을 반환한다.
MONTHS_BETWEEN(date1, date2) : 날짜와 날짜 사이의 기간을 ‘월(month)’로 나타낸다.
NEXT_DAY(date, char) : 해당일을 기준으로 명시된 요일의 다음 날짜를 반환한다.
* 변환 함수 (Conversion Functions)
TO_CHAR(datetime, ‘fmt’) : DATE 관련 데이터 타입을 VARCHAR2 데이터 타입으로 변환한다.
TO_CHAR(number, ‘fmt’) : NUMBER 타입을 VARCHAR2 데이터 타입으로 변환한다.
CAST({expr | MULTISET(subquery)} AS type_name) : 데이터 형식이나 collection 형식을 다른 데이터 형식이나 collection 형식으로 변환한다.
CONVERT(char, dest_char, [source_char]) : 문자세트를 다른 문자세트로 문자열을 변환한다.
TO_DATE(char, [fmt, ‘nlsparam’]) : char를 날짜형 데이터 타입값으로 변환한다.
TO_NUMBER(expr, [fmt, ‘nlsparam’]) : expr을 NUMBER 데이터형의 값으로 변환한다.
* 기타 함수 (Miscellaneous Single-row Functions)
DECODE(expr, search, result, default) : expr과 search 값을 비교하여 같으면 result 값을 반환한다. 같지 않다면 default 값을 반환한다.
NVL(expr1, expr2) : expr1이 NULL 값인 경우 expr2의 값을 반환한다.
==========================================================
3.2 집합 함수(Aggregate Functions)
-> 하나 이상의 행으로부터 하나의 결과를 반환한다.
(1) AVG 함수
AVG(expr)
-> 하나 이상의 값들로부터 평균값을 반환한다.
ex) EMPLOYEES 테이블로부터 급여 평균을 구한다.
SQL> SELECT AVG(salary)
2 FROM employees;
AVG(SALARY)
———–
6461.68224
AVG(expr) OVER(analytical_clause)
-> 분석 함수로 사용된 예. AVG() 함수는 분석 함수로도 사용할 수 있다.
ex) 부서(department_id)별 평균값을 얻어 반환하는 예이다 평균값의 소수점 이하 처리를 위해 소수점 이하에서 반올림 처리하여 반환하고 있다.
SQL> SELECT employee_id, department_id, salary,
2 ROUND(AVG(salary) OVER(PARTITION BY department_id), 0) “AvgByDeptid”
3 FROM employees
4 WHERE department_id IN (10, 20, 30);
EMPLOYEE_ID DEPARTMENT_ID SALARY AvgByDeptid
———– ————- ———- ———–
200 10 4400 4400
201 20 13000 9500
202 20 6000 9500
117 30 2800 4150
118 30 2600 4150
116 30 2900 4150
119 30 2500 4150
114 30 11000 4150
115 30 3100 4150
9 rows selected.
(2) RANK 함수
RANK(expr) WITHIN GROUP(ORDER BY expr)
-> 전체 값을 대상으로 각 값의 순위를 반환한다.
ex) 급여가 $3,000인 사람의 상위 급여 순위를 나타낸다.
SQL> SELECT RANK(3000) WITHIN GROUP(ORDER BY salary DESC) “rank”
2 FROM employees;
rank
———-
82
RANK() OVER(query_partition_clause order_by_clause)
-> 특정 급여의 순위가 아니 전체 급여에 대해 하나하나 순위를 알고 싶을 때에도 RANK() 함수를 사용한다.
ex) 전체 사원의 급여 순위를 나타낸다.
SQL> SELECT employee_id, salary, RANK() OVER(ORDER BY salary) “rank”
2 FROM employees;
(3) SUM, MIN, MAX, COUNT 함수
-> 참고로 하나 이상의 행으로부터 합계를 반환하는 SUM() 함수와 최대값/최소값을 반환하는 MAX()/MIN() 함수가 있다. 또 전체 행의 수를 반환하는 COUNT() 함수도 있다.
ex) 연도별 입사자의 수와 최대, 최소 급여를 나타내보라.
SQL> SELECT TO_CHAR(hire_date, ‘YYYY’), COUNT(last_name), MAX(salary), MIN(salary)
2 FROM employees
3 GROUP BY TO_CHAR(hire_date, ‘YYYY’);
TO_C COUNT(LAST_NAME) MAX(SALARY) MIN(SALARY)
—- —————- ———– ———–
2000 11 10500 2200
1987 2 24000 4400
1997 28 13500 2500
1994 7 12000 6500
1991 1 6000 6000
1995 4 7900 3100
1990 1 9000 9000
1989 1 17000 17000
1999 18 11000 2100
1996 10 14000 3300
1993 1 17000 17000
TO_C COUNT(LAST_NAME) MAX(SALARY) MIN(SALARY)
—- —————- ———– ———–
1998 23 10000 2500
ex) 이번에는 각 연도 별 입사자 수를 나타내 보라.
SQL> SELECT TO_CHAR(hire_date, ‘YYYY’), COUNT(employee_id)
2 FROM employees
3 GROUP BY TO_CHAR(hire_date, ‘YYYY’);
TO_C COUNT(EMPLOYEE_ID)
—- ——————
2000 11
1987 2
1997 28
1994 7
1991 1
1995 4
1990 1
1989 1
1999 18
1996 10
1993 1
TO_C COUNT(EMPLOYEE_ID)
—- ——————
1998 23
ex) 2000년 이후 입사자를 대상으로 직무별로 급여의 합을 얻어보라. 해당 직무에 소속한 사원의 수도 함께 나타내라.
SQL> SELECT job_id, SUM(salary), COUNT(employee_id)
2 FROM employees
3 WHERE TO_CHAR(hire_date, ‘YYYY’) >= 2000
4 GROUP BY job_id;
JOB_ID SUM(SALARY) COUNT(EMPLOYEE_ID)
———- ———– ——————
SH_CLERK 5400 2
SA_MAN 10500 1
SA_REP 38900 6
ST_CLERK 4400 2
* 다음은 자주 사용되는 집합 함수를 요약한 표이다.
함수이름 : 설명
AVG(expr) : 하나 이상의 값들로부터 평균값을 반환한다.
AVG(expr) OVER(analytical_clause) : 하나 이상의 값들로부터 평균값을 반환한다.
RANK(expr) WITHIN GROUP(ORDER BY expr) : 전체 값을 대상으로 각 값의 순위를 반환한다.
SUM : 하나 이상의 행으로부터 합계를 반환한다.
MIN : 하나 이상의 행으로부터 최소값을 반환한다.
MAX : 하나 이상의 행으로부터 최대값을 반환한다.
COUNT : 하나 이상의 행으로부터 전체 행의 수를 반환한다.
===============================================================
3.3 분석 함수(Analytical Functions)
-> Oracle 8.1.6부터 지원되는 분석용 함수는 기존의 SELECT로 해결하기 어려웠던 문제를 쉽게 처리하도록
지원한다. 예를 들어 대량의 데이터를 대상으로 누적 합계, 순위, 이동 평균 들을 구하려고 할 때 기존의 SELECT를 이용하면
프로그래밍이 복잡할 뿐만 아니라 성능도 보장되지 않았다. 이때 분석용 함수를 사용하게 되면 간결한 프로그래밍과 향상된 성능을
보장받을 수 있게 된다.
분석용 함수는 행의 집단에 대해 연산이 이루어진다는 점에서 일반 그룹 함수와 유사하다. 그러나 일반 그룹 함수는 하나의 집단에
대해 하나의 결과가 RETURN 되지만 분석용 함수는 하나의 집단에 대해 여러 가지 기준을 적용해서 여러 개의 결과가
RETURN 될 수 있다. 이때 처리 대상이 되는 행의 집단을 윈도우(Window)라고 지칭한다.
분석용 함수는 하나의 Query에서 ORDER BY 절 직전에 수행된다. 즉, JOIN, WHERE, GROUP BY,
HAVING이 처리된 결과에 대해 분석용 함수가 적용되고 마지막으로 ORDER BY가 수행된다는 것이다. 따라서 분석용 함수는
SELECT 절이나 ORDER BY 절에만 나타날 수 있다.
Analytic-Function(<Argument>. <Argument>, …)
OVER(<Query-Partition-Clause> <Order-By-Clause> <Windowing-Clause>)
(1) FIRST_VALUE 함수
FIRST_VALUE(expr) OVER(analytic_clause)
-> 정렬된 값들 중 첫 번째 값을 반환한다.
ex) 전체 사원의 급여와 함께 각 부서의 최고 급여를 나타내고 비교하시오.
SQL> SELECT employee_id, salary,
2 FIRST_VALUE(salary)
3 OVER(PARTITION BY department_id ORDER BY salary DESC)
4 “Highsal_Departmentid”
5 FROM employees;
-> 질의문을 보면 Highsal_Departmentid 칼럼은 부서별(PARTITION BY
department_id)로 급여에 대해 내림차순 정렬하여(ORDER BY salary DESC) 얻은 값 중 첫 번째
값(FIRST_VALUE), 즉, 해당 부서의 최고 급여를 반환한다.
이와는 반대로 LAST_VALUE() 함수는 정렬된 값들 중 마지막 값을 반환한다.
(2) COUNT 함수
COUNT(expr) OVER (analytic_clause)
-> 조건을 만족하는 행의 수를 반환한다.
SQL> SELECT employee_id, salary, COUNT(*) OVER(ORDER BY salary) “count”
2 FROM employees
3 WHERE department_id = 50;
(3) SUM 함수
SUM(expr) OVER(analytic_clause)
-> 조건을 만족하는 행의 합을 반환한다.
ex) 특정 값을 누적하여 결과를 보여주는 사례이다.
SQL> SELECT employee_id, last_name, salary,
2 SUM(salary) OVER(ORDER BY employee_id) “acc_salary”
3 FROM employees;
ex) 위 결과에 더해 부서별 누적 결과를 함께 보고자 한다.
SQL> SELECT employee_id, last_name, department_name, salary,
2 SUM(salary) OVER(ORDER BY d.department_id, employee_id) “acc_salary”,
3 SUM(salary) OVER(PARTITION BY d.department_id ORDER BY employee_id) “acc_dept_salary”
4 FROM employees e JOIN departments d
5 ON d.department_id = e.department_id;
-> 위 예제에서는 ‘SUM(SALARY) OVER(PARTITION BY DEPARTMENT_ID ORDER BY
EMPLOYEE_ID)’ 부분이 핵심적인 내용이다. 즉, 부서별로 SUM(SALARY)를 구하기 위해 전체 집합을 여러
파티션으로 나누었으며 이를 위해 PARTITION BY DEPARTMENT_ID 절을 사용했다. 그리고 이렇게 나누어진 각
파티션에 대해 함수를 사용해서 파티션 별로 누적 합계를 구한 것이다.
상위 n 개의 행을 구하고자 할때 분석용 함수를 사용하는 방법이다. 예를 들어 ‘월급 상위 n 명’, ‘입사일자 순으로 n
명’, ‘매출 상위 n 개 품목’등을 구하고자 할 경우 분석용 함수는 아주 좋은 해결책이 된다. 특히 같은 순위의 행이 여러
개라면 월급 순위 3위까지 구할 경우, 실제 결과는 4개를 넘어설 수도 있었던 것이다. 순위와 관련된 함수는
ROW_NUMBER(), RANK(), DENSE_RANK() 등이 있다.
ex) 부서별로 급여를 많이 받는 순서대로 나타내시오.
SQL> SELECT employee_id, last_name, department_name, salary,
2 ROW_NUMBER() OVER(PARTITION BY d.department_id ORDER BY salary DESC) AS Rank
3 FROM employees e JOIN departments d
4 ON d.department_id = e.department_id;
부서별로 상위 n 명이 필요하다고 한다면 우측 마지막 칼럼인 RANK를 이용하여 제한하면 된다. 예를 들어 ‘Shipping’ 부서를 대상으로 급여를 많이 받는 순으로 얻고자 한다면 다음과 같다.
SQL> SELECT employee_id, last_name, department_name, salary,
2 RANK() OVER(PARTITION BY d.department_id ORDER BY salary DESC) AS Rank
3 FROM employees e JOIN departments d
4 ON d.department_id = e.department_id
5 WHERE department_name = ‘Shipping’;
* 다음은 자주 사용되는 분석 함수를 요약한 표이다.
함수이름 : 설명
FIRST_VALUE(expr) OVER(analytic_clause) : 정렬된 값들 중 첫 번째 값을 반환한다.
COUNT(expr) OVER(analytic_clause) : 조건을 만족하는 행의 수를 반환한다.
SUM(expr) OVER (analytic_clause) : 조건을 만족하는 행의 합을 반환한다.
LAST_VALUE(expr) OVER(analaytic_clause) : 윈도우에서 정렬된 값중에서 마지막 값을 반환한다.
RANK() OVER(order_by_clause) : 값의 그룹에서 값의 순위를 계산한다.
ROW_NUMBER() OVER([query_partition_clause[ order_by_clase) : ORDER BY 절에서 지정된 행의 순위 순서로 각 행에 고유한 순서를 1부터 할당한다.
DENSE_RANK() OVER([query_partition_clause] order_by_clause) : 값의 그룹에서
값의 순위를 계산한다. RANK와는 달리 같은 순위가 둘 이상 있어도 다음 순위는 1만 증가하여 반환한다.
======================================================
3.4 정규 표현식(Regular Expression)
-> Oracle 10g에서 새로 도입된 정규 표현식(Regular Expression)을 표현하기 위해 Oracle은 기존 함수의 기능을 확장한 새로운 함수를 제공한다.
(1) REGEXP_LIKE 함수
REGEXP_LIKE(srcstr, pattern [, match_option])
srcstr : 검색하고자 하는 값을 말한다.
pattern : Regular Expression Operator를 통해 문자열에서 특정 문자를 보다 다양한 pattern으로 검색하는 것이 가능함.
match_option : 찾고자 하는 문자의 대소문자 구분이 기본으로 설정되어 있다. 대소문자를 구분할 필요가 없다면 ‘i’ 옵션 사용을 지정한다.
ex) 제품의 이름 중에 ‘SS’다음에 ‘P’를 포함하지 않은 문자열을 찾는 경우이다.
SQL> SELECT product_name
2 FROM oe.product_information
3 WHERE REGEXP_LIKE(product_name, ‘SS[^P]’);
PRODUCT_NAME
————————————————–
SS Stock – 3mm
SS Stock – 1mm
Spreadsheet – SSS/S 2.1
Spreadsheet – SSS/V 2.1
Spreadsheet – SSS/CD 2.2B
Spreadsheet – SSS/V 2.0
Spreadsheet – SSS/S 2.2
7 rows selected.
[^expression]의 의미는 expression이 부정되는 경우를 나타낸다.
ex)이번 경우는 제품 이름에 ‘SS’다음 ‘P’나 ‘S’를 포함하는 문자열을 찾는 경우이다.
SQL> SELECT product_name
2 FROM oe.product_information
3 WHERE REGEXP_LIKE(product_name, ‘SS[PS]’);
PRODUCT_NAME
————————————————–
Spreadsheet – SSP/V 2.0
Spreadsheet – SSS/S 2.1
Spreadsheet – SSS/V 2.1
Spreadsheet – SSS/CD 2.2B
Spreadsheet – SSS/V 2.0
Spreadsheet – SSS/S 2.2
Spreadsheet – SSP/S 1.5
7 rows selected.
[]의 의미는 [] 안에 명시되는 하나의 문자라도 일치하는 것이 있으면 이를 나타내므로, 위 경우 ‘SS’로 시작하면서 ‘P’나 ‘S’를 포함하는 문자열이 있으면 위의 조건을 만족하게 되는 것이다.
그럼, REGEXP_LIKE 함수의 예를 살펴보자.
ex) 만약 고객의 개인 정보를 입력하는 과정에서 명확하지 않은 이메일(email) 주소를 입력한 경우, 고객 테이블의 경우 중복을 방지하는 제약 조건만 설정되어 있어 이러한 경우에도 정상적인 입력이 가능하다
SQL> INSERT INTO customers
2 (customer_id, cust_first_name, cust_last_name, cust_email)
3 VALUES(9999, ‘Christian’, ‘Patel’, ‘for.econet-gmail.com’);
이 경우 정확한 메일 주소의 입력을 위해 REGEXP_LIKE 정규 표현 식을 이용하여 주소에 ‘@’이 포함되도록 설정해보자.
SQL> ALTER TABLE customers
2 ADD CONSTRAINT cust_email_addr
3 CHECK(REGEXP_LIKE(cust_email, ‘@’)) NOVALIDATE;
Table altered.
테이블에 제약 조건이 추가되었다면, 다시 앞의 신규 교객 입력 SQL문을 실행해 보라.
SQL> INSERT INTO customers(customer_id, cust_first_name, cust_last_name, cust_email)
2 VALUES(9998, ‘Christian’, ‘Patel’, ‘for.econet-gmail.com’);
INSERT INTO customers(customer_id, cust_first_name, cust_last_name, cust_email)
*
ERROR at line 1:
ORA-02290: check constraint (OE.CUST_EMAIL_ADDR) violated
제약 조건에 위배되어 입력이 불가능함을 알 수 있다. 참고로 지정해 준 제약 조건은 아래와 같이 해제할 수 있다.
SQL> ALTER TABLE customers DROP CONSTRAINT cust_email_addr;
Table altered.
(2) REGEXP_SUBSTR 함수
REGEXP_SUBSTR(srcstr, pattern [, position [, occurrence [, match_option]]])
position : Oracle이 문자열에서 특정 문자를 어디에서 찾아야 하는지 위치를 나타낸다. 기본은 1로 설정되어 있으므로, 문자열의 처음부터 검색을 시작한다.
occurrence : 검색하고자 하는 문자열에서 특정 문자의 발생 pattern이다. 기본은 1로 설정되어 있으며, 이는 Oracle이 문자열에서 첫 번째 발생 pattern을 찾는다는 의미이다.
ex) 고객의 이메일 중 아이디만 얻고자 한다. REGEXP_SUBSTR 함수는 고객의 이메일(cust_email)에 저장된 문자열에서 ‘@’이 아닐 때까지 읽어 고객의 아이디만을 아래와 같이 얻고 잇다.
SQL> SELECT cust_email, REGEXP_SUBSTR(cust_email, ‘[^@]+’) “REGEXP_SUBSTR”
2 FROM oe.customers
3 WHERE nls_territory = ‘SWITZERLAND’;
(3) REGEXP_REPLACE 함수
REGEXP_REPLACE(srcstr, pattern [,replacestr [,position [,occurrence [, match_option]]]])
replacestr : 대체하고자 하는 문자열을 나타낸다.
ex) 사용자가 문자열을 입력 과정에서 종종 띄었기가 일정하지 않아 공백이 두 문자나 그 이상의 발생하는 경우가 있다. 이 경우 공백을 일정하게 유지될 수 있도록 설정해 준다면 문자열을 읽기에 편리하다.
* 다음은 정규 표현식에 사용되는 함수를 요약한 표이다.
함수 이름 : 설명
REGEXP_LIKE : LIKE 연산자와 유사하며, 표현 식 패턴(regular expression pattern)을 수행하여, 일치하는 값을 반환한다.
REGEXP_SUBSTR : SUBSTR 함수의 기능을 확장한다. 주어진 문자 열을 대상으로 정규 표현식 패턴을 수행하여, 일치하는 하위 문자열을 반환한다.
REGEXP_REPLACE : 주어진 문자 열을 대상으로 정규 표현 식 패턴을 조사하여, 다른 문자로 대체한다.
REGEXP_INSTR : 정규 표현을 만족하는 부분을 위치를 반환한다.
정규 표현식에 관한 상세한 내용은 다음의 사이트를 참고한다.
Oracle Database Documentation Library:
http://www.oracle.com/pls/db10g/homapage
C Oracle Regular Expression Support:
http://download-west.oracle.com/docs/cd/B14117_01/server.101/b10759/ap_posix.htm
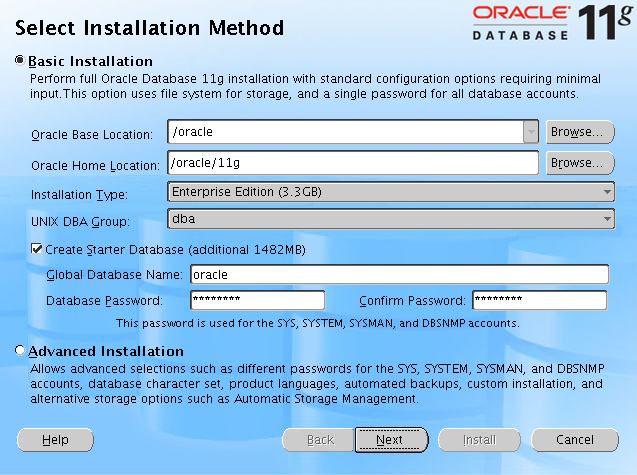
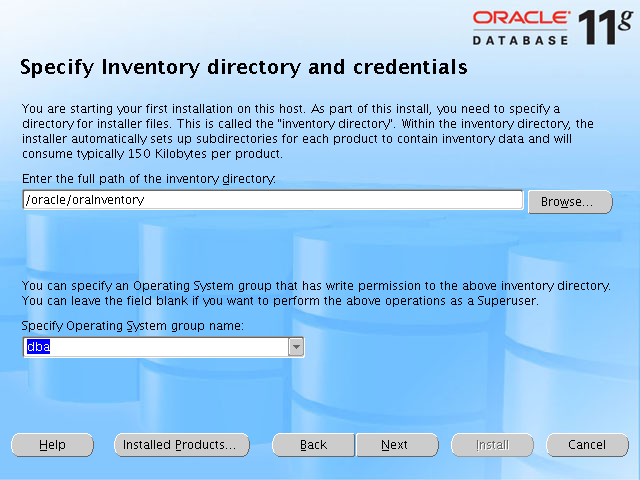
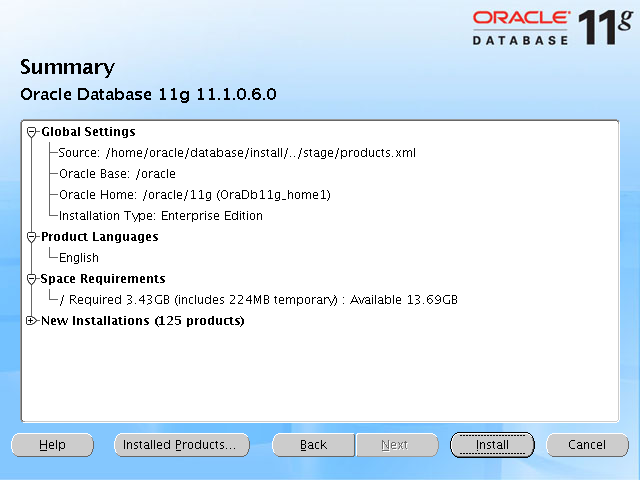
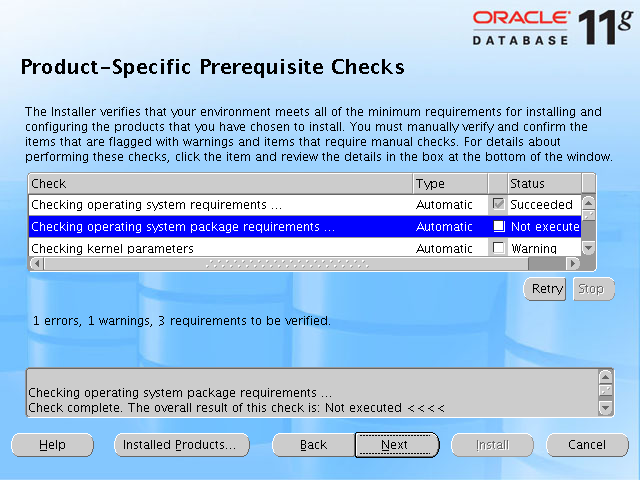
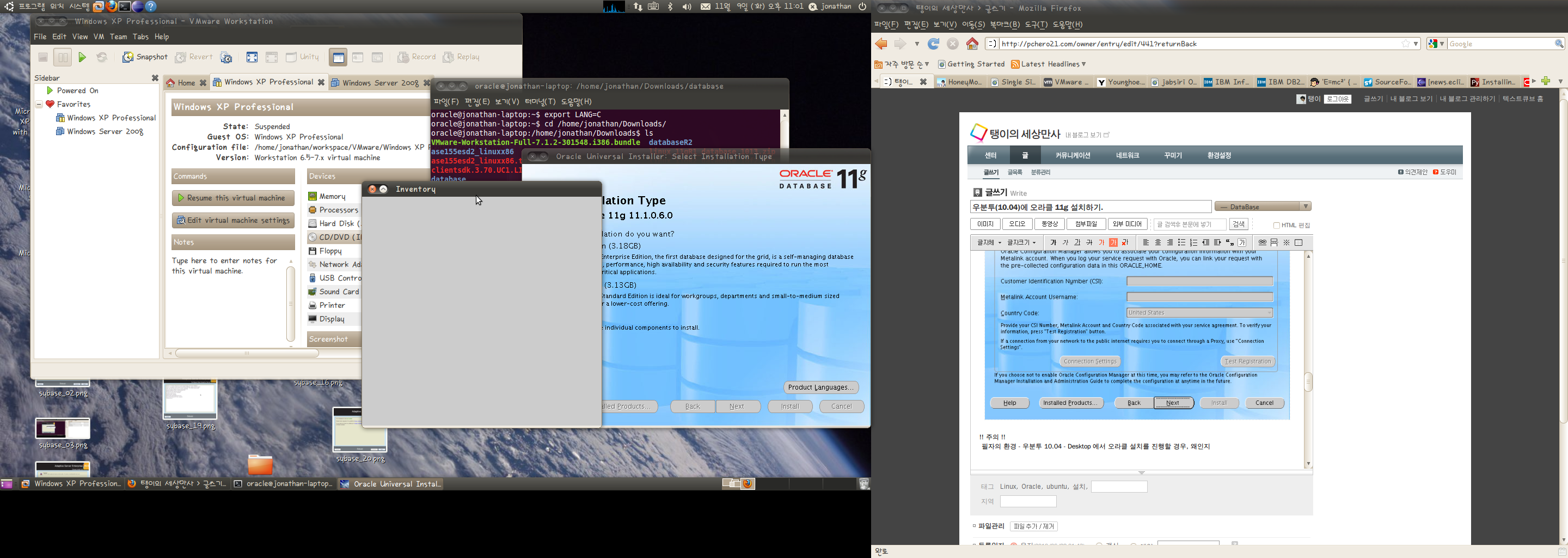 왼쪽의 화면처럼 창이 하나 뜨고 창의 안쪽에는 아무런 화면이나 메시지가 나타나지 않는 문제였다.
왼쪽의 화면처럼 창이 하나 뜨고 창의 안쪽에는 아무런 화면이나 메시지가 나타나지 않는 문제였다.
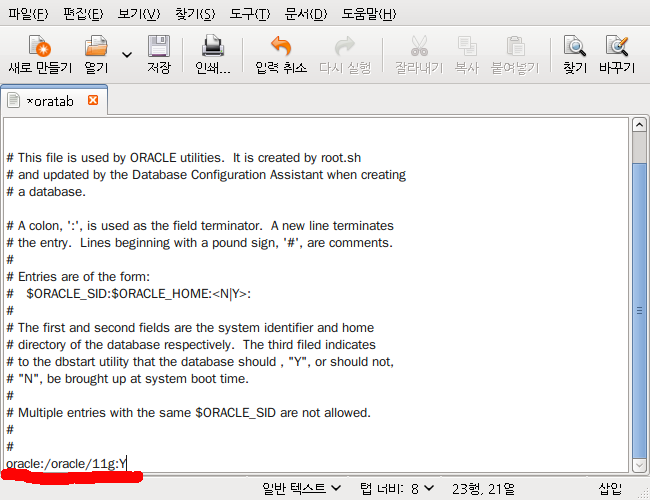 보이는 것처럼 oracle:/oracle/11g:N 을 oracle:/oracle/11g:Y 로 변경하면 된다.
보이는 것처럼 oracle:/oracle/11g:N 을 oracle:/oracle/11g:Y 로 변경하면 된다.