awk 는 1977년에 AT&T 연구소의 Alfred V.Aho, Peter J.Weinverger, Brain W.Kernighan 세 사람이 만들었다. awk 라는 이름도 이 세사람의 앞 글자로 만들어 졌다. 리눅스에서는 1986년 Paul Rubin 과 Jay Fenlason 에 의해 GNU 버전의 awk 가 만들어 졌다.
awk 는 일정한 규칙을 가지고 있는 데이터를 처리하여 계산, 통계, 비교분석 혹은 필터링을 통한 데이터 추출 등에 다양하게 사용될 수 있다. sed 와 비슷한 기능을 한다고 할 수 있으며 awk 와 sed 의 장점을 묶어서 만들어진 perl 로 발전되었지만 단순한 구조의 데이터의 경우 더 효과적으로 쓰일 수 있어서 지금도 많이 사용되고 있다.
awk 는 쉽고 유용하게 쓰일 수 있다. 단순히 명령어로 사용되거나 다른 스크립트에 sed 와 함께 다른 스크립트에 이용될 수 있고 awk 만의 스크립트 파일의 작성도 가능하다.
명령어 사용
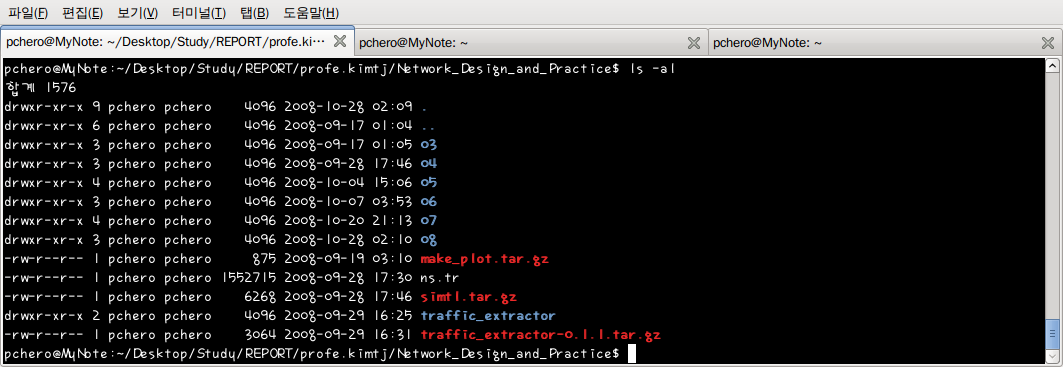
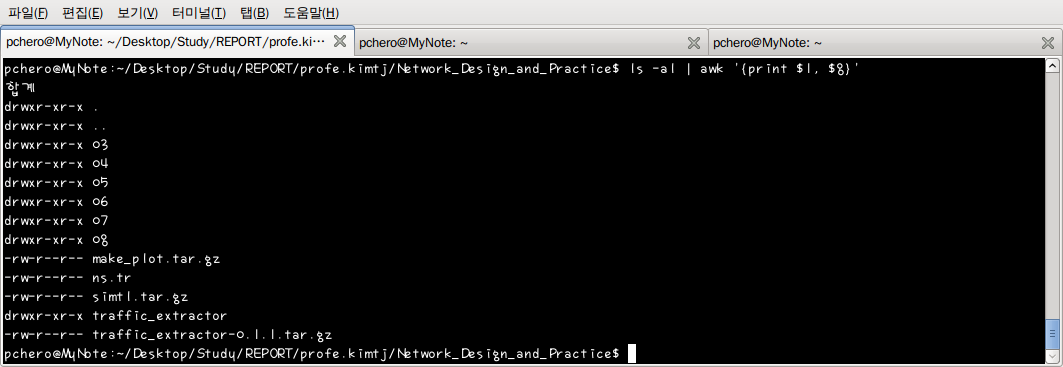
현재 디렉토리의 파일 정보를 보기 위해 ls -al 명령어를 이용하여 파일 목록을 출력한다. 이 목록 중 파일의 권한과 파일명만 보기를 원한다면 awk 를 이용해 어렵지 않게 편집할 수 있다. ls -al 명령으로 출력되는 데이터를 파이프(|)로 awk 가 받아 파일의 공백을 기준으로 나누어 첫 번째 필도와 8 번째 필도를 출력한다.
awk 로 필터링하여 파일의 권한과 파일명만 출력한다. 위와 같이 awk 는 라인을 받아 구분자를 통해 구분하고 print 명령으로 출력하게 된다.
ls -al 로 출력되는 행을 공백으로 구분하면 8가지의 필드로 구분된다. 각 필드는 공백을 기준으로 구분된다. $1 ~ $8 까지로 각 필드의 변수를 표현하며, $0 은 모든 필드를 말한다.
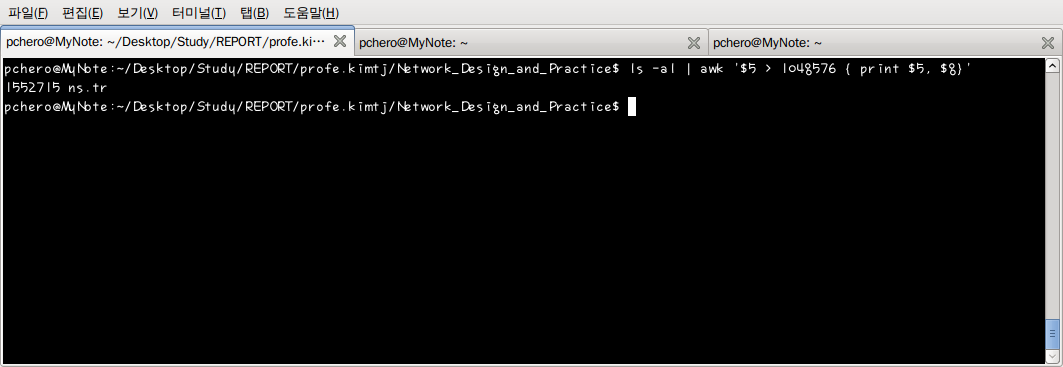
파일 목록 중 1 Mb 이상의 용량을 갖는 파일명과 용량을 출력하고 싶다면 awk 의 조건문을 사용하여 가능하다. 1 Mb = 1048576 bit 이기 때문에 용량을 나타내는 5번째 필드 중 1048576 보다 큰 라인을 출력하며 그 중 5번째와 9번째 필드만 출력한다.
awk 를 이용하면 문서의 특정 문자나 문자열을 검색하여 검색되어 나온 라인만 출력할 수 있다.
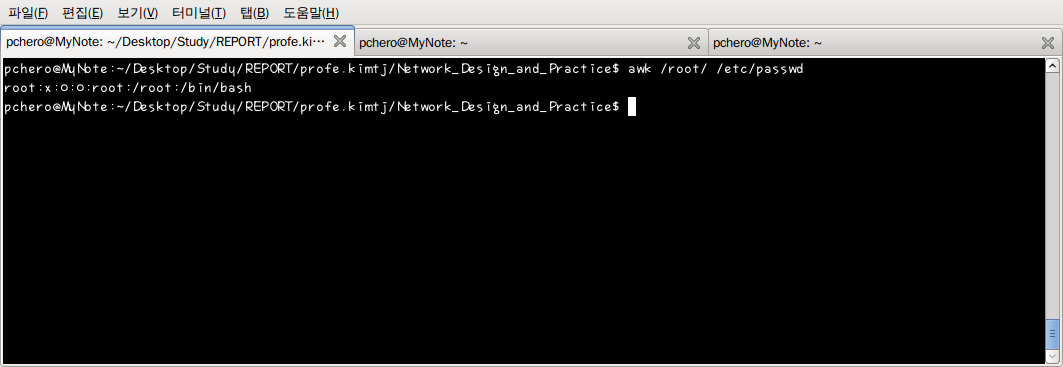
root 계정을 포함한 라인만 검색하여 출력하였다.
첫 번째 예제에서는 문자열 중 구분 되어 있는 필드를 지정하여 원하는 필드만 출력하였고 두 번째 예제에서는 보기를 원하는 패턴을 가진 라인만 검색하여 출력하였다. 이 두 가지를 조합하면 보기를 원하는 라인에 특정 필드만 출력이 가능하다.
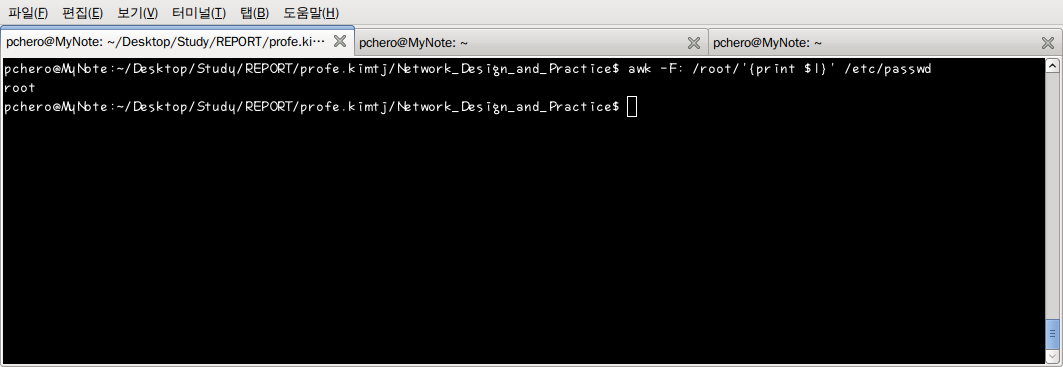
두 번째 예제는 /etc/passwd 파일을 root 라는 패턴으로 검색하여 root 라는 문자열을 포함한 라인만 출력되었다. “:표시로 구분지은 필드 중 제일 먼저 나오는 것이” 그룹명인데 다음 예제는 이 그룹명만 출력 되도록 만들었다.
-F 는 구분자를 정의한 옵션으로 기본은 공백을 사용하지만 이 파일과 같이 “-F:”로 구분자를 지정해 사용할 수 있다.
/root/ 로 검색한 패턴 부분에, 정규 표현식을 사용하면 더욱 자세한 패턴을 검색할 수 있다.
스크립트 파일 이용
=========================================================================================== 시작(Begin) | 시작 단계로서 전체 스크립트를 위한 정의 단계이다.(Preprocessor) ——————————————————————————————- 실행(Routin) | 실행단계로서 이 스크립트의 기능을 수행하는 단계라고 할 수 있다. ——————————————————————————————- 끝(End) | 마무리 단계이다. 결과를 출력한다. ===========================================================================================
awk 의 스크립트 구조는 시작, 실행, 마무리의 3단계로 나누어져 있다.
awk 는 여러 연산자나 루프 사용법 등이 C 와 같아 C 를 알고 있는 사용자라면 어려움 없이 사용할 수 있다.
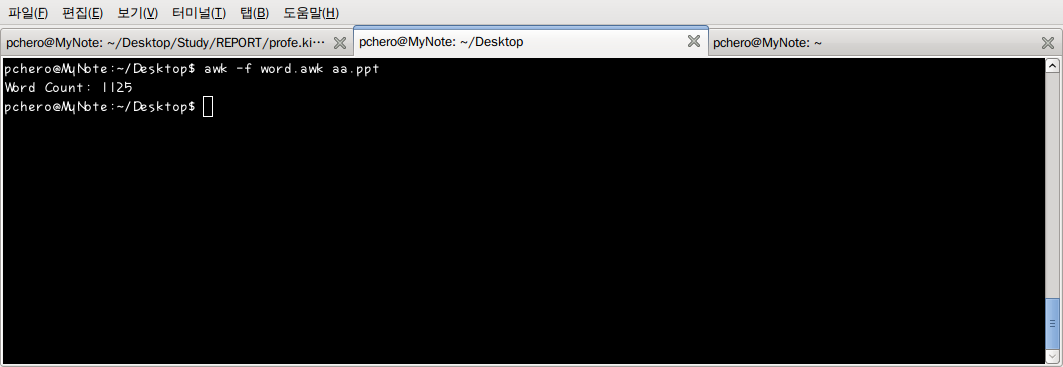
다음의 스크립트는 파일의 단어 수를 검사한다. wc 라는 명렁어로 쉽게 단어 개수를 체크해 볼 수 있지만 여기서는 간단한 awk 스크립트 예제로 awk 스크립트 사용법을 알아보자.
=========================================================================================== awk 스크립트 | 구조 | 설명 =========================================================================================== #!/bin/awk | 선언 | awk 로 스크립트가 실행될 수 있게 선언한다. ——————————————————————————————- BEGIN { | 시작 | 변수 word 를 0으로 초기화 한다. word = 0; | (Begin) | } | | ——————————————————————————————- { | 실행 | NF는 각 라인마다의 필드 수를 나타내는 awk 시스템 변수이다. awk 는 word += NF; | (Routin) | 구분자가 정의되어 있지 않을 때 공백을 구분자로 사용하므로 각 라인의 } | | 단어의 수가 NF 로 들어가고 “+=” 연산자에 의해서 마지막 라인의 단어 | | 갯수까지 더해준다. ——————————————————————————————- END { | 끝 (END) | 마무리 단계이다. 결과를 출력한다. print “Word Count: ” | | word;(End) | | } | | ===========================================================================================
작성된 스크립트는 -f 옵션으로 실행한다. wordcount.txt 라는 임의의 텍스트 문서를 방금 작성한 스크립트로 검사해 보자. 작성된 awk 스크립트 파일을 실행하려면 awk -f [스크립트 파일 이름] 형식으로 사용한다.
awk 시스템 변수
=============================================================================================== 변수 : 내용 =============================================================================================== $0 : 입력 라인 모두 $n : 입력 라인에서 n 번째 필드 값 ARGC : 명령 라인 인자 수를 갖는 변수 ARGV : 명령 라인의 인자를 포함하는 배열 ENVIRON : 환경변수들을 모아둔 관계형 배열 FILENAME : 현재 파일명 FS : 구분자 정의, 공백을 기본으로 사용 FNR : 입력파일의 레코드 총수(라인 수) NF : 현재 레코드 필드 수 NR : 현재 레코드 번호 OFMT : 숫자에 대한 출력 포멧 OFS : 출력 레코드 구분 (newline 을 기본으로 사용) RLENGTH : 지정한 패턴으로 검색되어 나온 문자열의 길이 RS : 입력 레코드 구분 (newline 을 기본으로 사용) RSTART : 지정한 패턴으로 검색되어 나온 문자열의 가장 앞부분 =============================================================================================
awk 연산자
c 를 참조하여 만들어 졌으므로 사용버이나 종류가 거의 같다.
=============================================================================================== 연산자 | 설명 =============================================================================================== ? | 조건연산 | 사용자로 등록된 아이디가 user1, user2, user3 로 되어 있고 그 중 검색하고 싶은 내용이 | 1, ,2, 3 중 어떤 것인지 명확하지 않을 경우 ? 를 이용하여 모두 검색할 수 있다. | # awk /user? /etc/passwd | user1:x:…… | user2:x:…… | user3:x:….. ———————————————————————————————– ||, &&, ! | 논리연산, or, and, not ———————————————————————————————– ~, !~ | 검색된 패턴에 부합되는 것을 참으로 사용하려면 “~”, 거짓으로 사용하려면 “!~”을 사용함. ———————————————————————————————– <. <=. >, >=. !=, == | 비교 연산자 ———————————————————————————————– +, -, *, /, %, ^ | 더하기, 빼기, 곱하기, 나누기, 나머지, 제곱 ———————————————————————————————– ++, — | 증가 연산자, 감소 연산자 ===============================================================================================
atq 를 사용하여 예약된 작업 목록을 확인한 후, 첫 번째 필드에 있는 작업 번호를 확인한다.
만약 작업번호가 27이라면 다음과 같이 삭제한다.
# atrm 27
관련 명령어
at : 작업을 특정 시간에 예약한다.
atq : 예약된 작업 목록을 보여 준다.
batch : 시스템 부하가 일정 이하일 때 명령을 실행한다.
cron : 정기적으로 예약된 작업을 실행한다.
예약 작업 시간의 결정
작업의 예약 실행은 시스템의 과부하를 피해 한가한 시간에 작업을 실행하기 위해서 이다. 그러므로 거의 밤 시간에 설정하는 경우가 대부분이다. 그러나 여러 사용자가 예약작업을 설정할 수 있을 경우 예약 시간은 새벽 3시 혹은 4시로 정형화 되는 경우가 많다. 이렇게 야간이라도 특정시간에 부하가 몰리는 경우 시스템에 문제가 생길 수 있다. 그러므로 예약 작업 시간을 결정할 때는 새벽 3시 35분 4시 11분 등으로 분까지 설정하여 같은 시간에 작업이 몰리는 것을 피해야 한다.