*iptables
iptables 방화벽은 넷필터 프로젝트(Netfilter Project, http://www.netfilter.org)에서 개발됐으며, 2001년 1월의 리눅스 2.4 커널 배포 시점부터 리눅스의 일부분으로 제공됐다.
iptables와 넷필터라는 단어 간의 차이는 리눅스 커뮤니티에서 다소 혼란의 원인이었다. 리눅스가 제공하는 모든 종류의 패킷 필터링과 맹글링(mangling) 도구의 공식적인 프로젝트명이 넷필터다. 하지만 이 단어는 네트워킹 스택으로 함수를 후킹(hooking)하는 데 사용할 수 있는 리눅스 커널 내부의 프레임워크를 말하기도 한다. 한편 iptables는 패킷에 대한 연산(필터링 등)을 수행하게 설계된 함수를 네트워킹 스택으로 후킹하기 위해 넷필터 프레임워크를 사용한다. 넷필터는 iptables가 방화벽 기능을 구현할 수 있게 프레임워크를 제공한다고 생각할 수 있다.
넷필터가 트래픽 자체를 필터링하지는 않는다. 넷필터는 커널 내부의 적절한 부분에 후킹되게 트래픽을 필터링할 수 있는 기능을 가능케 해줄 뿐이다. 넷필터 프로젝트는 연결 추적이나 기록(logging)과 같은 커널 인프라스트럭처의 일부를 제공하기도 한다. 모든 iptables 정책은 특화된 패킷 처리를 수행하기 위해 이런 넷필터의 기능을 사용할 수 있다.
* iptables를 이용한 패킷 필터링
사용자는 iptables 방화벽을 이용해서 리눅스 시스템과 연동하는 IP 패킷에 대해 강력한 제어 기능을 갖출 수 있다. 이러한 제어는 리눅스 커널 내부에 구현된다.
iptables 정책은 정렬된 규칙집합으로부터 생성된다. 규칙은 특정 분류의 패킷에 대해 취해야 할 조치를 커널에게 알려준다. 하나의 iptables 규칙은 테이블 내에 있는 하나의 체인에 적용된다. iptables 체인은 순서대로 공통적인 특징(예를 들어 리눅스 시스템으로 라우팅되거나 리눅스 시스템에서 외부로 나가는 것)을 공유하는 패킷들과 비교되는 규칙 모음이다.
– 테이블
테이블(table)은 패킷 필터링이나 네트워크 주소 변환(NAT, Network Address Translation)과 같은 기능의 광범위한 범주를 기술하는 iptables 구성소다. filter, nat, magle, raw 와 같은 4개의 테이블이 있다. 필터링 규칙은 filter 테이블에 적용된다. NAT 규칙은 nat 테이블에 적용되며, 패킷 데이터를 변경하는 특수 규칙은 mangle 테이블에 적용된다. 끝으로 텟필터의 연결추적 하위시스템과 독립적으로 기능해야 하는 규칙은 raw 테이블에 적용된다.
– 체인
각 테이블은 자신만의 고유(build-in) 체인(chain) 집합을 가지지만 사용자는 INPUT_ESTABLISHED 나 DMZ_NETWORK 와 같은 공통 태그와 관련된 규칙집합을 만들기 위해 사용자 정의 체인을 생성할 수 있다. 패킷 필터링에서 가장 중요한 고유 체인은 filter 테이블의 INPUT, OUTPUT, FORWARD 체인이다.
— INPUT 체인은 커널 내부에서 라우팅 계산을 마친 후 로컬 리눅스 시스템이 목적지인 패킷(즉, 로컬 소켓이 목적지인 패킷)에 적용된다.
— OUTPUT 체인은 리눅스 시스템 자체가 생성하는 패킷을 위해 예약된 것이다.
— FORWARD 체인은 리눅스 시스템을 통과하는 패킷을 관리한다.(즉, 한 네트워크를 다른 네트워크와 연결하기 위해 iptables 방화벽을 사용해서 두 네트워크 간의 패킷이 방화벽을 통과해야 하는 경우)
좀 더 견고한 iptables 설치를 위해 필요한 두 개의 추가 체인으로 nat 테이블의 PREROUTING과 POSTROUTING 체인이 있다. 이 체인은 커널 내부에서 IP 라우팅 계산을 수행하기 전과 휴에 패킷 헤더를 수정하기 위해 사용한다.
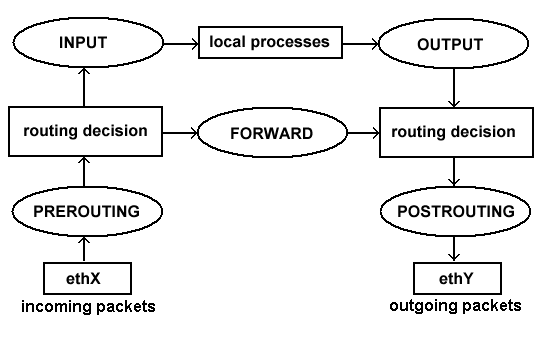
iptables 패킷 흐름
– 매치
모든 iptables 규틱은 타겟(target)과 함께 규칙을 따르는 패킷을 어떻게 처리할지 iptables에게 알려주는 매치(Match)들을 가진다. iptables 매치는 iptables가 규칙 타겟에 의해 명시되는 동작에 따라 패킷을 처리하기 위해서 패킷이 만족해야 하는 조건이다. 예를 들어 규칙을 TCP 패킷에만 적용하고자 한다면 –protocol 매치를 사용하면 된다.
각 매치는 iptables 명령 행에서 명시된다.
–source (-s) : 출발지 IP 주소나 네트워크와의 매칭
–destination (-d) : 목적지 IP 주소나 네트워크와의 매칭
–protocol (-p) : 특정 프로토콜 값과의 매칭
–in-interface (-i) : 입력 인터페이스(예를 들어 eth0)
–out-interface (-o) : 출력 인터페이스
–state : 연경 살태와의 매칭
–string : 애플리케이션 계층 데이터 바이트 순서와의 매칭
–comment : 커널 메모리 내의 규칙가 연계되는 최대 256 바이트의 주석
– 타겟
iptables 는 패킷이 규칙과 일치할 때 동작을 취하는 타겟(Target)을 지원한다.
ACCEPT : 패킷이 본래 라우팅대로 진행된다.
DROP : 패킷을 버린다. 더 이상 어떤 처리도 수행되지 않으며 수신 스택이 관련된 데에 한해서는 패킷이 전송된 적도 없는 것과 같다.
LOG : 패킷을 syslog에 기록한다.
REJECT : 패킷을 버리고 이와 동시에 적절한 응답 패킷(예를 들어 TCP 연결의 경우 TCP 재설정[Reset] 패킷, UDP 패킷의 경우 ICMP 포트 도달 불가[Port Unreachable] 메시지)을 전송한다.
RETRUN : 호출 체인 내에서 패킷 처리를 계속한다.
* 기본 iptables 정책
– 정책 요구사항
몇 개의 클라이언트와 두 개의 서버로 구성된 네트워크를 위한 효과적인 방화벽 설정에 필요한 요구사항을 정의해보자. 서버(웹서버와 DNS서버)는 외부 네트워크에서 접근할 수 있어야 한다. 내부 네트워크에 있는 시스템은 방화벽을 통해 외부 서버로 다음과 같은 유형의 트래픽을 시작할 수 있어야 한다.
— 도메인 네임 시스템(DNS, Domain Name System) 질의
— 파일 전송 프로토콜(FTP, File Transfer Protocol) 전송
— 네트워크 시간 프로토콜(NTP, Network Time Protocol) 질의
— 시큐어 쉘(SSH, Secure SHell) 세션
— 단순 메일 전송 프로토콜(SMTP, Simple Mail Transfer Protocol) 세션
— whois 질의
위에 나열한 서비스 외에는 어떤 트래픽도 허용하지 않아야 한다. 내부 네트워크나 방화벽에서 바로 시작된 세션은 iptables가 상태유지형으로 추적해야 한다(유효한 상태를 따르지 않는 패킷은 기록한 후 최대한 빨리 버려야 한다). 또 NAT 서비스도 제공해야 한다.
이와 더불어 방화벽은 외부 IP 주소로 포워딩되는 내부 네트워크로부터의 스푸팅된 패킷에 대한 제어를 구현해야 한다.
— 방화벽 자체는 네트워크로부터 SSH를 통해 접속할 수 있어야 한다. 그러나 인증을 위해 fwknop를 실행하고 있지 않는 한 그 밖에 어떤 곳에서도 접속할 수 없어야 한다.
— 방화벽은 내부와 외부 네트워크 모두로부터 ICMP 에코 요청(Echo Request)을 수용해야 한다. 그러나 에코 요청을 제외하면 어떤 출발지 IP 주소로부터의 원하지 않은(unsolicited) ICMP 패킷도 모두 버려야 한다.
— 끝으로 잘못 전달된 패킷, 포트 스캔, 명시적으로 혀용된 것이 아닌 기타 연결 시도를 모두 기록하고 버리기 위해 방화벽은 기볼 기록 후 버리기 전략(log and drop stance)으로 설정해야 한다.
– iptables.sh 스크립트 프리앰블(Preamble)
iptables.sh 스크립트를 시작하기 위해 IPTABLES와 MODPROBE(iptables 와 modprobe 바이너리의 경로), INT_NET(내부 서브넷 주소와 마스크)과 같이 세 개의 변수를 정의하면 좋다. 이 변수들은 스크립트 전반에 걸쳐 사용된다.
먼저 기존의 iptables 규칙이 실행 중인 커널에서 제거되고 INPUT, OUTPUT, FORWARD 에 대한 필터링 정책이 DROP 으로 설정된다. 또 modprobe 명령어를 사용해서 연결추적 모듈을 로딩한다.
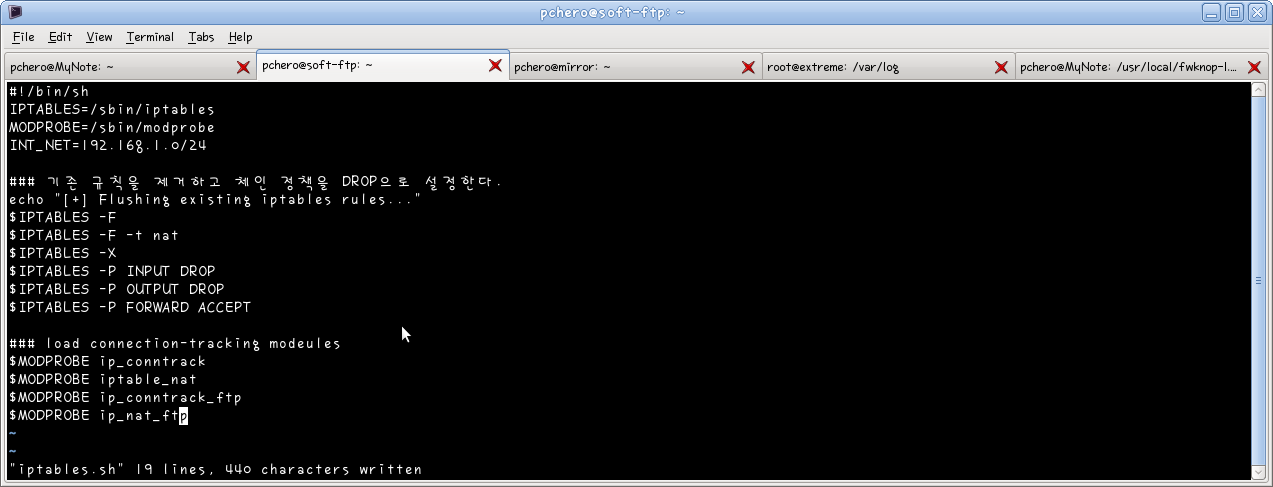
– ip_conntrack : iptables에서 현재 테이블에 등록된 IP의 연결을 추적하기 위한 모듈
– ip_conntrack_ftp, ip_nat_ftp : iptables 에서 ftp 사용을 가능하게 하는 모듈. NAT 설정을 사용하지 않는다면 ip_nat_ftp 모듈을 적재하지 않아도 된다.
-> FTP의 경우 서버와 클라이언트 모두가 방화벽 안에 있으면 접속은 되지만, 파일 목록이나 내용 전송.. 등등이 안되는 현상이 벌어진다. 위의 적재된 모듈들은 이것을 피하기 위한 모듈이다.
– INPUT 체인
INPUT 체인은 로컬 시스템을 목적으로 하는 (즉, 커널의 라우팅 계산 결과 패킷이 로컬 IP 주소를 목적지로 한다는 것을 안 후) 패킷이 로컬 소켓과 통신할 수 있는지 여부를 결정하는 iptables 구성소다. INPUT 체인의 첫 번째 규칙이 iptables로 하여금 모든 패킷을 버리게 하는 것이라면(또는 INPUT 체인의 정책 설정이 DROP으로 설정돼 있다면) 시스템과 IP 통신(TCP, UDP, ICMP 등)을 통해 직접 통신하려는 모든 시도는 실패하게 된다. 주소 결정 프로토콜(ARP, Address Resolution Protocol) 역시 이더넷 네트워크상 어디에나 존재하는 중요한 트래픽이다. 그러나 ARP는 네트워크 계층이 아니라 데이터 링크 계층에서 동작하며, iptables는 IP 트래픽과 상위 프로토콜만 필터링하기 때문에 ARP 트래픽은 필터링할 수 없다.
그러므로 ARP 요청과 응답은 iptables 정책과 무관하게 전송되고 수신된다(arptables를 이용해서 ARP 트래픽을 필터링할 수도 있다).
– iptables 는 커널이 MAC 주소 확장을 활성화한 상태로 컴파일된 경우에만 데이터 링크 계층의 MAC 주소에 기반해서 IP 패킷을 필터링할 수 있다. 2.4 커널 시리즈에서는 사용자가 직접 MAC 주소 확장을 활성화해야 하지만 2.6 커널 시리즈에서는 기본적으로 활성화돼 있다.
프리앰블을 완성한 후 iptables 쉘 스크립트 개발을 계속하기 위해 다음의 명령어를 사용해 INPUT 체인을 설정한다.
##### INPUT 체인 #####
echo “[+] Setting up INPUT chain…”
### 상태 추적 규칙
$IPTABLES -A INPUT -m state –state INVALID -j LOG –log-prefix “DROP INVALID ” –log-ip-options –log-tcp-options
$IPTABLES -A INPUT -m state –state INVALID -j DROP
$IPTABLES -A INPUT -m state –state ESTABLISHED,RELATED -j ACCEPT
### 안티 스푸핑 규칙
$IPTABLES -A INPUT -i eth2 -s ! $INT_NET -j LOG –log-prefix “SPOOFED PKT “
$IPTABLES -A INPUT -i eth2 -s ! $INT_NET -j DROP
### ACCEPT 규칙
#ftp
$IPTABLES -A INPUT -p tcp –dport 20 –syn -m state –state NEW -j ACCEPT
$IPTABLES -A INPUT -p tcp –dport 21 –syn -m state –state NEW -j ACCEPT
#ssh
$IPTABLES -A INPUT -p tcp –dport 22 –syn -m state –state NEW -j ACCEPT
#whois
$IPTABLES -A INPUT -p tcp –dport 43 –syn -m state –state NEW -j ACCEPT
#domain
$IPTABLES -A INPUT -p tcp –dport 53 –syn -m state –state NEW -j ACCEPT
$IPTABLES -A INPUT -p udp –dport 53 -m state –state NEW -j ACCEPT
#http
$IPTABLES -A INPUT -p tcp –dport 80 –syn -m state –state NEW -j ACCEPT
$IPTABLES -A INPUT -p udp –dport 80 -m state –state NEW -j ACCEPT
#https
$IPTABLES -A INPUT -p tcp –dport 443 –syn -m state –state NEW -j ACCEPT
#rsync
$IPTABLES -A INPUT -p tcp –dport 873 –syn -m state –state NEW -j ACCEPT
$IPTABLES -A INPUT -p udp –dport 873 -m state –state NEW -j ACCEPT
#icmp
$IPTABLES -A INPUT -p icmp –icmp-type echo-request -j ACCEPT
### 기본 INPUT LOG 규칙
$IPTABLES -A INPUT -i ! lo -j LOG –log-prefix “DROP ” –log-ip-options –log-tcp-options
앞서 정의한 방화벽 정책 요구사항에 따르면 iptables 는 연결을 상태유지형으로 추적해야 한다. 즉, 유효한 상태와 일치하지 않는 패킷은 조기에 기록하고 버려야 한다. 이는 “### 상태 추적 규칙 주석” 밑의 3개의 iptables 명령어가 수행한다. OUTPUT과 FORWARD 체인에 대해서도 이와 유사한 세 개의 명령어를 볼 수 있다. 이런 각 규칙은 INVALID, ESTABLISHED, RELATED 기준과 함께 상태 매칭을 이용한다.
INVALID 상태는 현존하는 어떤 연결에도 속했다고 식별할 수 없는 패킷에 적용된다. 예를 들어 느닷없이 도착한 TCP FIN 패킷(즉, 어떤 TCP 세션의 일부도 아닌 TCP FIN 패킷)은 INVALID 상태와 일치된다. ESTABLISHED 상태는 넷필터 연결 추적 하위시스템이 양방향 모두에서 패킷(예를 들어 데이터가 교환되는 TCP 연결의 승인[acknowledgement] 패킷)을 본 후에만 패킷에 대해 활성화된다. RELATED 상태는 넷필터 연결추적 하위시스템에서 새로운 연결을 시작하고 있는(그러나 이 연결이 이미 존재하는 연결과 연결돼 있는) 패킷(예를 들어 어떤 서버도 바인딩되지 않은 UDP 소켓에 패킷이 전소오딘 후 반환된 ICMP 포트 도달 불가 메시지)을 기술한다.
다음으로 안티스푸핑 규칙을 추가했으므로 내부 네트워크에서 시작된 패킷은 반드시 192.168.1.0/24 서브넷에 속하는 출발지 주소를 가진다.
또한 “### ACCEPT 규칙” 에는 서비스를 제공 하는 일련의 포트번호의 ACCEPT 규칙이 나와 있다. SSH 연결을 수용하는 규칙은 iptables의 –syn 명령 행 인자와 함께 NEW 상태가 일치될 때(연결추적 하위 시스템이 관련된 데 한해서 패킷이 새로운 연결을 시작하고 있음을 의미한다)만 이 규칙이 일치된다.
끝에는 기본 LOG 규칙이 나와 있다. 스크립트 프리앰블에서 봤듯이 INPUT 체인 내의 규칙에 의해 혀용되지 않는 패킷은 이 체인에 할당된 DROP 정책에 의해 버려진다는 사실을 상기하자. 이는 OUTPUT 과 FORWARD 체인에 할당된 DROP 정책에도 적용된다. 위에서 알 수 있듯이 INPUT 체인의 설정은 특정 포트로의 접속만 수용하고 원치 않는 패킷은 기록하고 버리면 되기 때문에 매우 쉽다.
– iptables.sh 스크립트에 대해 한 가지 주의해야 할 것은 모든 LOG 규칙이 –log-ip-options 와 –log-tcp-options 를 명령행 인자로 사용한다는 점이다. 이 인자를 통해 iptables syslog 메시지는 LOG 규칙과 일치하는 패킷이 IP 와 TCP 헤더에 IP 와 TCP 옵션을 포함하는 경우 이를 포함하게 된다. 이 기능은 psad 가 수행하는 공격 탐지와 수동적 OS 핑거프린팅의 동작 모두에 중요하다.
– OUTPUT 체인
OUTPUT 체인은 iptables가 로컬 시스템에 의해 생성되 네트워크 패킷에 커널 수준의 제어를 할 수 있게 해준다. 예를 들어 로컬 사용자가 외부 시스템으로 SSH 세션을 초기화하면 OUTPUT 체인을 이용해서 아웃 바운드 SYN 패킷을 허용하거나 거부할 수 있다.
iptables.sh 에서 OUTPUT 체인 규칙 집합을 구성하는 명령어는 아래와 같다.
###### OUTPUT 체인 ######
echo “[+] Setting up OUTPUT chain…”
### 상태 추적 규칙
$IPTABLES -A OUTPUT -m state –state INVALID -j LOG –log-prefix “DROP INVALID ” –log-ip-options –log-tcp-options –log-tcp-sequence
$IPTABLES -A OUTPUT -m state –state INVALID -j DROP
$IPTABLES -A OUTPUT -m state –state ESTABLISHED,RELATED -j ACCEPT
### 외부로 나가는 연결을 허용하기 위한 ACCEPT 규칙
#ftp
$IPTABLES -A OUTPUT -p tcp –dport 20 –syn -m state –state NEW -j ACCEPT
$IPTABLES -A OUTPUT -p tcp –dport 21 –syn -m state –state NEW -j ACCEPT
#ssh
$IPTABLES -A OUTPUT -p tcp –dport 22 –syn -m state –state NEW -j ACCEPT
#whois
$IPTABLES -A OUTPUT -p tcp –dport 43 –syn -m state –state NEW -j ACCEPT
#domain
$IPTABLES -A OUTPUT -p tcp –dport 53 –syn -m state –state NEW -j ACCEPT
$IPTABLES -A OUTPUT -p udp –dport 53 -m state –state NEW -j ACCEPT
#http
$IPTABLES -A OUTPUT -p tcp –dport 80 –syn -m state –state NEW -j ACCEPT
$IPTABLES -A OUTPUT -p udp –dport 80 -m state –state NEW -j ACCEPT
#https
$IPTABLES -A OUTPUT -p tcp –dport 443 –syn -m state –state NEW -j ACCEPT
#rsync
$IPTABLES -A OUTPUT -p tcp –dport 873 –syn -m state –state NEW -j ACCEPT
$IPTABLES -A OUTPUT -p udp –dport 873 -m state –state NEW -j ACCEPT
$IPTABLES -A OUTPUT -p icmp –icmp-type echo-request -j ACCEPT
### 기본 OUTPUT LOG 규칙
$IPTABLES -A OUTPUT -o ! lo -j LOG –log-prefix “DROP ” –log-ip-options –log-tcp-options –log-tcp-sequence
– FORWARD 체인
FORWARD 체인은 시스템을 통해 라우팅을 시도하는 패킷과 관련된 iptables 규칙을 담당한다. filter 테이블의 iptables FORWARD 체인은 방화벽 인터페이스를 통해 포워딩되는 패킷에 대한 접근 제어 기능을 제공한다.
##### FORWARD 체인 #####
echo “[+] Setting up FORWARD chain…”
### 상태 추적 규칙
$IPTABLES -A FORWARD -m state –state INVALID -j LOG –log-prefix “DROP IINVALID ” –log-ip-options –log-tcp-options
$IPTABLES -A FORWARD -m state –state INVALID -j DROP
$IPTABLES -A FORWARD -m state –state ESTABLISHED,RELATED -j ACCEPT
### 안티 스푸핑 규칙
$IPTABLES -A FORWARD -i eth2 -s ! $INT_NET -j LOG –log-prefix “SPOOFED PKT “
$IPTABLES -A FORWARD -i eth2 -s ! $INT_NET -j DROP
### ACCEPT 규칙
# 기본적으로 FORWARD 에 한해서는 모든 포트에 ACCEPT를 적용한다.
### 기본 LOG 규칙
$IPTABLES -A FORWARD -i ! lo -j LOG –log-prefix “DROP ” –log-ip-options –log-tcp-options
– 네트워크 주소 변환 (NAT, Network Address Translation)
iptables 정책을 구성하는 마지막 단계는 라우팅 불가능 내부 주소 192.168.1.0/24 를 라우팅 가능한 외부 210.125.X.X 주소로 변환할 수 있게 하는 것이다. 이는 외부 클라이언트에서 시작된 웹서버나 DNS서버로의 인바운드 연결과 내부 네트워크의 시스템에서 시작된 아웃바운드 연결 모두에 적용된다. 내부 시스템에서 시작한 연결의 경우에는 출발지 NAT(SNAT, Source NAT) 타겟을 사용하며 외부 시스템에서 시작한 연결의 경우에는 목적지 NAT(DNAT, Destination NAT) 타겟을 사용한다.
iptables nat 테이블을 모든 종류의 NAT 규칙을 위한 것으로 PREROUTING 과 POSTROUTING 이라는 두 체인을 포함한다. PREROUTING 체인은 패킷이 어느 인터페이스를 통해 전송될지 경정하기 위해 아직 커널의 라우팅 알고리즘을 통과하지 않은 패킷에 nat 테이블의 규칙을 적용하는 데 사용한다. 이 체인에서 처리되는 패킷은 아직 filter 테이블의 INPUT 이나 OUTPUT 체인과도 비교되지 않은 것이다.
POSTROUTING 체인은 패킷이 커널의 라우팅 알고리즘을 통과한 후 계산된 물리적 인터페이스를 통해 전송되려는 시점에서 패킷 처리를 담당한다. 이 체인이 처리하는 패킷은 filter 테이블의 OUTPUT 이나 FORWARD 체인의 요구사항(mangle 테이블과 같이 등록됐을 수 있는 다른 테이블이 강제하는 요구사항도 포함)을 통과한 것이다.
##### NAT 규칙 #####
echo “[+] Setting up NAT rules…”
$IPTABLES -t nat -A POSTROUTING -s $INT_NET -o eth3 -j MASQUERADE
POSTROUTING 규칙은 내부의 라우팅 불가능 네트워크에서 시작되며, 외부 인터넷을 목적지로 하는 연결이 IP 주소 210.125.
iptables 정책을 작성하는 최종 단계는 리눅스 커널의 IP 포워딩을 활성화하는 것이다.
##### 포워딩 #####
echo “[+] Enabling IP forwarding
echo 1 > /proc/sys/net/ipv4/ip_forward
– 정책 활성화
iptables의 최고 장점 중 하나는 iptables 명령어 실행을 통해 커널 내부에서 정책을 활성화하기가 매우 쉽다는 것이다. 무거운 사용자 인터페이스나 바이너리 파일 형식 또는 비대한 관리 프로토콜은 전혀 없다.
– iptables-save 와 iptables-restore
iptables.sh 스크립트의 모든 iptables 명령어는 새로운 규칙을 시작하거나 체인의 기본 정책을 설정하거나 이전 규칙을 제거하기 위해 한 번에 하나씩 실행된다. 각 명령어는 iptables 정책을 생성하기 위해 매번 별도의 iptables 사용자 바이너리 실행을 필요로 한다. 그러므로 이는 시스템 부팅 시에 정책을 빠르게 적용하는 최적의 방법은 아니다. 특히 iptables 규칙의 수가 수백 개에 이르면 이런 식으로 정책을 적용하는 것은 좋지 않다. iptables 프로그램과 동일한 디렉토리에 설치되는 iptables-save 와 iptables-restore 명령어에서 훨씬 더 빠른 방법을 제공한다. iptables-save 명령어는 실행 중인 정책의 모든 iptables 규칙을 사람이 읽을 수 있는 형태로 저장하는 파일을 생성한다. 이 형식은 iptables-restore 프로그램으로 해석(interpret)할 수 있다. iptables-restore 프로그램은 ipt.save 파일에 나열된 규칙을 실행 중인 커널 내부에서 활성화한다. iptable-restore 프로그램을 한 번만 실행하면 전체 iptables 정책을 커널에 재생성할 수 있으며, iptables 프로그램을 여러 번 실행하는 것은 필요치 않다. 그러므로 iptables-save 와 iptables-restore 명령어는 iptables 규칙집합을 빠르게 적용하는 데 이상적이며, 다음과 같은 두 명령어로 나타낼 수 있다.
root@extreme:~# iptables-save > ipt.save
root@extreme:~# cat ipt.save > iptables-restore
ipt.save 파일의 내용은 iptables 테이블에 의해 구성되며, 각 테이블을 위한 부분은 다시 iptables 체인에 의해 구성된다. 별표(*)와 테이블명(예를 들어 filter)으로 시작하는 행은 ipt.save 파일에서 특정 테이블을 위한 부분의 시작을 나타낸다. 이런 행 다음에는 해당 테이블에 속한 체인을 위한 패킷과 바이트 수를 추적하는 행이 나온다.
ipt.save 파일의 다음 부분에는 체인에 의해 구성된 모든 iptables 규칙의 완전한 기술이 나온다. iptables-restore 는 이 부분을 이용해서 실제 iptables 규칙집합을 재생성한다(iptables-save 에 -c 옵션을 사용한 경우 규칙에 대한 패킷과 바이트 수 까지 포함해서 재생성한다).
끝으로 COMMIT을 이용해서 ipt.save 파일의 iptables 테이블 기술 부분을 끝낸다. 이 행은 해당 테이블과 관련된 모든 정보에 대한 종료 표시자다.
다음은 ipt.save 파일의 일부분이다.
# Generated by iptables-save v1.4.1.1 on Sat Sep 26 13:17:35 2009
*filter
:INPUT DROP [226586:80181793]
:FORWARD ACCEPT [0:0]
:OUTPUT DROP [9881:717618]
:FWSNORT_FORWARD – [0:0]
:FWSNORT_FORWARD_ESTAB – [0:0]
:FWSNORT_INPUT – [0:0]
:FWSNORT_INPUT_ESTAB – [0:0]
:FWSNORT_OUTPUT – [0:0]
:FWSNORT_OUTPUT_ESTAB – [0:0]
-A INPUT -i ! lo -j FWSNORT_INPUT
-A INPUT -p udp -m udp –dport 80 -m string –string “/etc/shadow” –algo bm –to 65535 -j LOG –log-prefix “ETC_SHADOW “
-A INPUT -p tcp -m tcp –dport 80 -m state –state ESTABLISHED -m string –string “/etc/shadow” –algo bm –to 65535 -j LOG –log-prefix “ETC_SHADOW “
-A INPUT -m state –state INVALID -j LOG –log-prefix “DROP INVALID ” –log-tcp-options –log-ip-options
-A INPUT -m state –state INVALID -j DROP
-A INPUT -m state –state RELATED,ESTABLISHED -j ACCEPT
-A INPUT -i eth0 -p tcp -m tcp –dport 20 –tcp-flags FIN,SYN,RST,ACK SYN -m state –state NEW -j ACCEPT
-A INPUT -i eth0 -p tcp -m tcp –dport 21 –tcp-flags FIN,SYN,RST,ACK SYN -m state –state NEW -j ACCEPT
-A INPUT -i eth0 -p tcp -m tcp –dport 22 –tcp-flags FIN,SYN,RST,ACK SYN -m state –state NEW -j ACCEPT
-A INPUT -i eth0 -p tcp -m tcp –dport 43 –tcp-flags FIN,SYN,RST,ACK SYN -m state –state NEW -j ACCEPT
-A INPUT -i eth0 -p tcp -m tcp –dport 53 –tcp-flags FIN,SYN,RST,ACK SYN -m state –state NEW -j ACCEPT
-A INPUT -i eth0 -p udp -m udp –dport 53 -m state –state NEW -j ACCEPT
-A INPUT -i eth0 -p tcp -m tcp –dport 80 –tcp-flags FIN,SYN,RST,ACK SYN -m state –state NEW -j ACCEPT
-A INPUT -i eth0 -p udp -m udp –dport 80 -m state –state NEW -j ACCEPT
-A INPUT -i eth0 -p tcp -m tcp –dport 443 –tcp-flags FIN,SYN,RST,ACK SYN -m state –state NEW -j ACCEPT
-A INPUT -i eth0 -p tcp -m tcp –dport 873 –tcp-flags FIN,SYN,RST,ACK SYN -m state –state NEW -j ACCEPT
-A INPUT -i eth0 -p udp -m udp –dport 873 -m state –state NEW -j ACCEPT
-A INPUT -p icmp -m icmp –icmp-type 8 -j ACCEPT
-A INPUT -i ! lo -j LOG –log-prefix “DROP ” –log-tcp-options –log-ip-options
-A FORWARD -i ! lo -j FWSNORT_FORWARD